一般而言,定义一个距离函数d(x,y),需要满足以下几个准则:
1. d(x,x) = 0 ;//到自己的距离为0
2. d(x,y)>=0 // 距离要非负
3. 对称性,d(x,y) = d(y,x) //如果A到B距离是a,那么B到A的距离也应该是a
4. 三角形法则(两个之和大于第三边) d(x,k)+ d(k,y) >= d(x,y)
满足这4个条件的距离函数很多,一般有几类是比较常见的,通常来自比较直观的形象,如平面的一个两点的直线距离。下面讨论应用比较广泛的几类距离或相似性度量函数,欧拉距离,余弦函数cosine,Pearson函数,Jaccard index,edit distance。如果一个对象d(如:一篇文档)表示成一个n维的向量(d1,d2,….,dn),每一个维度都为对象的一个特征,那么这些度量函数极容易得到应用。
1.范数和欧拉距离
欧拉距离,来自于欧式几何(就是我们小学就开始接触的几何学),在数学上也可以成为范数。如果一个对象对应于空间的一个点,每一个维度就是空间的一个维度。特殊情况,如果n=1,那么,小学我们就学过,直线上两个点的距离是|x1-x2|。推广到高纬情况,一个很自然的想法是,把每一个维度的距离加起来不就可以呢。这就形成了传说中的一范数:

看,是不是很简单。有一范数就有二范数,三范数。。。无穷范数。其实,二范数来的更加直观,我们都知道二维空间,三维空间的两点的距离公式。他就是二范数,在二维三维上的形式了。

好了,一鼓作气,p范数(p-norm)
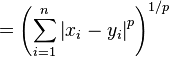
无穷范数:
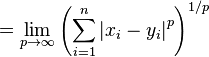

空间两点的距离公式(2-范数),是最常用的距离公式,他就是传说中的欧拉距离。多简单。
2. cosine similarity
cosine similarity是备受恩宠啊,在学向量几何的时候,应该接触过这个神奇的公式
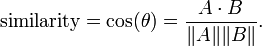
分子是两个向量的点积,||A||是向量的长度,这个公式神奇的地方是,随着角度的变化的,函数是从-1,1变化的。向量夹角的余弦就是两个向量的相似度。cosine similarity 说,如果两个向量的夹角定了,那么无论一个向量伸长多少倍,他们的相似性都是不变的。所以,应用cosine 相似性之前,要把对象的每一个维度归一化。在搜索引擎技术中,cosine 相似性在计算查询和文档的相似性的时得到了很好的应用。对查询语句而言(如:“明天天气如何”),它的每一个维度是对应词的tf-idf.
cosine similarity的一个扩展是,Tonimoto系数:

其实也没什么大不了。T(A,B)的分母是大于等于 cos similarity的分母,但且仅仅但 A,B长度一样是才相等。这就意味着,Tonimoto系数考虑了两个向量的长度差异,长度差异越大相似性约小。
3. Jacard index
Jacard 相似性直观的概念来自,两个集合有多相似,显然,Jacard最好是应用在离散的变量几何上。先看公式(不要头晕)
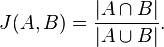
分子是集合交集,分母是集合并集,画个图,马上就明白咋回事了。
和Jacard index 相似的一个公式是Dice‘ coefficient, 它也很直观,

4. Pearson correlation coefficient
学过概率论的人都知道,有均值,反差,还有相关系数,相关系数就是就是描述两组变量是否线性相关的那个东西。相关系数的优点是,它跟变量的长度无关,这个都点像cosine相似性。有一个应用是,比如一个商品推荐系统,要给用户A推荐相应的产品,首先要通过对商品的打分,找到与A相似k个用户。但是有些人,可能天生喜欢打高分,有些人偏向于打低分,为了消除这个问题 相关系数是一个很好的度量方法。列公式,
![/rho_{X,Y}={/mathrm{cov}(X,Y) /over /sigma_X /sigma_Y} ={E[(X-/mu_X)(Y-/mu_Y)] /over /sigma_X/sigma_Y},](http://upload.wikimedia.org/math/1/7/7/17709e96782a6a8bcd39904c5f2383e6.png)
这个公式貌似和cosine 是有点关系的。至于如何关联,我就不讨论了。参看correlation
5. 编辑距离或者Levenshtein distance
编辑距离说的两个字符串的相似程度。串A通过删除,增加,和修改变成串B的可以度量函数(一般是是通过多少步能将A变成B 也可以对每一个编辑步骤加权)wikipedia上有非常好的描述,这里就不再赘述。Levenshtein Distance. 与之相关的字符串相似性方法还有Jaro-Winkler distance。
6 SimRank 相似
SimRank来自图论,说两个变量相似,因为他们链接了同一个或相似的节点。这个算法需要需要重点讨论。下次在说。
分享到:













相关推荐
论文研究-基于多维形态特征表示的时间序列相似性度量.pdf, 特征表示和相似性度量是时间序列数据挖掘的基础工作, 其质量好坏直接影响后期的挖掘结果. 利用正交多项式回归...
运动轨迹数据的相似性度量.docx
目标再确认中的优化扩散距离相似性度量.pdf
基于孪生神经网络的时间序列相似性度量.pdf
基于装配关系的CAD模型的相似性度量.pdf
网络中的节点相似性度量
针对时间序列相似性度量中动态时间规整(DTW)算法在序列时间轴偏移较大时易产生病态路径及匹配不准确的问题,根据心电信号自身的特性,提出一种基于心电信号最显著特征的优先匹配法。为减小算法时间复杂度,根据...
针对传统面貌相似性度量方法容易受主观影响以及半自动面貌特征点提取方法存在标定不准确等问题,提出一种基于自适应邻域特征描述子的三维面貌相似性度量的方法。该方法将待比较面貌模型统一到法兰克福坐标系下,并...
不确定信息对Vague值(集)相似性度量的影响非常复杂、难以刻画,现有的度量方法大多都忽略了该因素。为此,在已有主要研究方法的基础上尝试以二次投票模型为背景考虑了不确定信息对Vague值(集)相似性的影响,提出...
针对传统的动态时间弯曲算法的性能容易受到离群点以及局部噪声点的影响,同时对于复杂数据的处理能力较差,提出基于形态距离及自适应权重的相似性度量算法。该算法首先利用l1趋势滤波对原始待比较序列进行降维、压缩...
提出一种基于概率距离及融合镜头时空特征的镜头相似性度量方法。横向方面,构造镜头加权颜色直方图来表示时间信息并使用直方图交计算镜头时间相似性;纵向方面,通过非线性映射将空间特征向量映射到高维空间进行高斯...
针对现有经典的时序数据相似性度量方法共同主成分分析(CPCA)和二维奇异值分解(2DSVD)中存在无法保存时序数据集合中蕴涵的某些重要局部特征的问题,提出了基于数据分块方式的CPCA方法和2DSVD方法。该算法首先对...
时间序列的相似性度量是时间序列分析的基础工作之一,是进行相似匹配的关键。针对欧几里德距离描述分段趋势的不足和各种模式距离对应分段之间距离值的离散化问题,提出一种基于形态相似距离的时间序列相似性度量方法...
目前,时间序列的相似性大多是在原始序列上进行判断和比较的,原始序列维度较高,计算量大,不利于相似性比较。提出了新的关键点(转折点或极值点)算法,除利用常用的极值法求非单调序列的关键点外,还提出了求单调...
提出了一种计算英文句子间相似度的方法。基于句子所传递的信息——其描述的...实验表明,提出的方法与目前计算句子间相似度的方法相比更加符合人工判断句子间相似度的过程,表现出更高的准确性,达到了较高的性能指标。
台风相似性度量方法的研究对防灾减灾、辅助决策等具有重要意义,台风相似性的研究大多集中在台风路径的相似性度量上。首先,梳理影响台风相似性度量的多个要素,提出了基于多元时间序列的台风数据描述方法;其次,...
时间序列相似性度量领域中,现有的算法对各类相似性变形的识别能力有限。为了能有效支持识别多种相似性形变,提出涨落模式(FP)的概念,以涨落模式保存原序列的趋势变化信息,利用最长公共子序列算法计算涨落模式的...
【毕业设计】基于CNN和词向量的句子相似性度量源码【毕业设计】基于CNN和词向量的句子相似性度量源码【毕业设计】基于CNN和词向量的句子相似性度量源码【毕业设计】基于CNN和词向量的句子相似性度量源码【毕业设计】...
时间序列相似性度量在挖掘时间序列模式,提取时间序列关联关系上发挥着重要作用。分析了当前主流的时间序列相似性度量算法,分别指出了各度量算法在度量时序数据相似性时存在的缺陷,并提出了基于数学形态学的时间...